AIで早期胃がん領域の高精度検出に成功
早期発見・領域検出で早期治療に大きく貢献
2018年7月20日
理化学研究所
国立がん研究センター
理化学研究所(理研)光量子工学研究センター画像情報処理研究チームの横田秀夫チームリーダー、竹本智子研究員、国立がん研究センター東病院消化管内視鏡科の矢野友規科長、池松弘朗医長、堀圭介医員らの共同研究チーム(注)は、少数の正解データにより構築された人工知能(AI)による、早期胃がんの高精度な自動検出法を確立しました。
本研究成果は、検診における胃がんの見逃しを減らすことで、早期発見、早期治療につながると期待できます。
早期胃がんは、進行性胃がんや大腸がんなどと比較すると形態的特徴が多彩で炎症との判別が難しく、内視鏡画像検査では専門医でも発見しにくいことがあります。今回、共同研究チームは機械学習[1]の方法の一つ、ディープラーニング[2]を使って、内視鏡画像から早期胃がんを自動検出する方法を考えました。ディープラーニングを画像中の物体検出へ応用する場合、一般には数十から数百万枚の正解画像が学習用データとして必要ですが、早期胃がんの場合、良質の正解画像を大量に収集することは困難です。そこで、少数の正解画像から小領域をランダムに切り出し、さらにデータ拡張技術を利用して画像を約36万枚まで増やしました。その画像をコンピュータに学習させた結果、陽性的中率(コンピュータが「がん」と判断した画像中、実際に「がん」であった割合)は93.4%、陰性的中率(コンピュータが「正常」と判断した画像中、実際に「正常」であった割合)は83.6%でした。さらに、早期胃がんの有無に加えて、その領域まで高精度で自動検出することに成功しました。
研究は、米国ハワイで開催される学会40th Annual International Conference of the IEEE Engineering in Medicine and Biology Societyにおいて研究成果の発表(7月20日付け:日本時間7月21日)を行います。
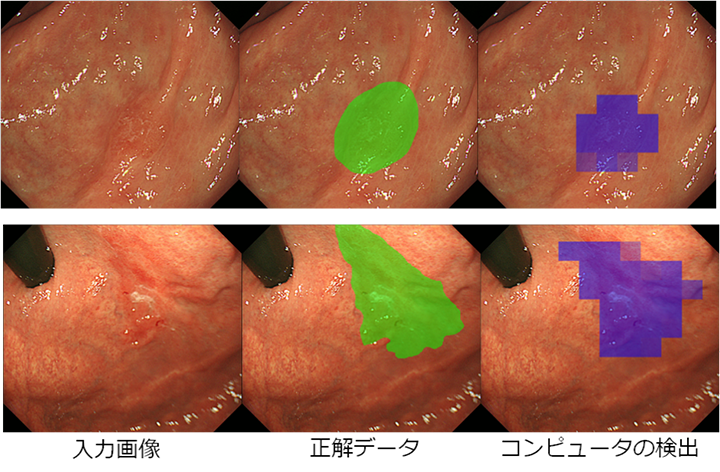
図 医師の診断(緑)とコンピュータの自動検出(紫)が示した早期胃がんの領域
(注)共同研究チーム
- 理化学研究所 光量子工学研究センター 画像情報処理研究チーム
- チームリーダー 横田 秀夫 (よこた ひでお)
(兼務副グループディレクタ- 科技ハブ産連本部 医科学イノベーションハブ推進プログラム 健康医療データ多層統合プラットフォーム推進グループ) - 研究員 竹本 智子 (たけもと さとこ)
- テクニカルスタッフI 西村 将臣 (にしむら まさおみ)
- 研修生 坂井 良匡 (さかい よしまさ)
- チームリーダー 横田 秀夫 (よこた ひでお)
- 国立がん研究センター東病院 消化管内視鏡科
- 科長 矢野 友規 (やの とものり)
- 医長 池松 弘朗 (いけまつ ひろあき)
- 医員 堀 圭介 (ほり けいすけ)
(注)研究支援
本研究は、国立がん研究センター研究開発費「内視鏡機器開発臨床試験体制基盤確立に関する研究(研究代表者: 矢野 友規)」による支援を受けて行われました。
1.背景
日本において胃がんは罹患率の高いがんの一つですが、早期の胃がん患者には自覚症状があまりありません。また、がんが進行して症状が現れた場合でも、胃炎や胃潰瘍の症状に似ていることから、がんだと分かったときにはかなり進行しているケースがあります。そのため、内視鏡を用いた検診時における胃がんの早期発見が望まれています。しかし、早期胃がんの画像診断の正確さは医師の経験に大きく依存し、専門医であっても発見が難しい場合があります。
最近、消化管の内視鏡画像診断にコンピュータによる機械学習を導入し、熟練した医師に迫る消化管腫瘍の診断、自動検出に成功した例がいくつか報告されています。しかし、早期胃がんでは精度の高い自動検出の成功例はほとんどありません。その理由として、機械学習に適用可能な早期胃がんに関するデータが十分に整備されていないこと、早期胃がんの多くは進行性胃がんや大腸がん、大腸ポリープなどと比べて形態的特徴や色の特徴が多彩で、正常粘膜における炎症との判別が難しいことなどが挙げられます。
そこで、共同研究チームは、ディープラーニング(深層学習)によって内視鏡画像から早期胃がんを自動検出する方法の開発に取り組みました。ディープラーニングとは、人間の脳神経回路を模倣したニューラルネットワークを多層的(狭義には4層以上)にして、コンピュータに学習させる機械学習の手法の一つです。学習させることで、コンピュータは画像や音声などのデータに含まれる特徴を段階的に認識できるようになり、最終的に正確な判断を実現させます。ディープラーニングはAIの発展を支える技術の一つで、さまざまな分野での実用化が進んでいます。
2.研究手法と成果
一般に、機械学習には数十~数百万枚の学習用データが必要ですが、早期胃がんの場合、学習用データの準備は簡単ではありません。そこで、共同研究チームはディープラーニングに分類される「畳み込みニューラルネットワーク(CNN)[3]」に基づく、少ない学習用データで学習させる新たな方法を採用しました。CNNは、特に画像の分類や識別で高い性能を発揮するディープラーニングの一つです。採用した学習方法を用いれば、早期胃がんの領域を正解として与えた正解画像と正常画像の計約200枚から、効率的な学習を可能にできると考えました。共同研究において、国立がん研究センターは早期胃がんの内視鏡画像の収集・分類を行い、理化学研究所はそれらの画像情報から早期胃がんの判別モデルを作成しました。
熟練の医師が内視鏡画像から早期胃がんを発見する場合、胃壁表面の粘膜のわずかな色の変化や粘膜表面の血管模様をもとに診断することが多いといわれています。そこで、早期胃がんの正解画像約100枚と正常画像約100枚から、「がんの部分」と「正常の部分」を確実に含む領域をランダムにそれぞれ約1万枚切り出し、合わせて約2万枚の画像(画像サイズ:224x224ピクセル)を取得しました(図1)。さらに、これらの画像に対してデータ拡張[4]という技術を利用し、画像を約36万枚まで増やしました。データ拡張は、早期胃がんの特徴である胃粘膜表面の血管模様などを保ちながら、元画像を加工することで新たな学習用データを作成する技術です。データ拡張の際に生じる元画像の加工は、ノイズや予期しない変化などに対してコンピュータを強くするうえでも役立ちます。
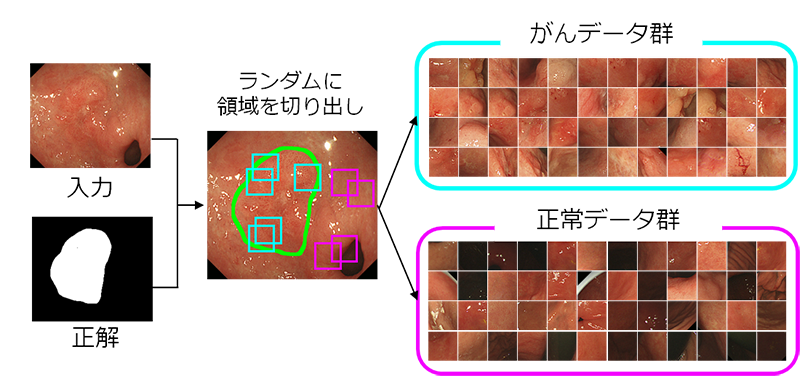
図1 早期胃がんの正解画像からランダムに切り出した「がん」と「正常」の学習用画像
入力画像に正解を与えた正解画像から、「がんの部分」(緑で囲まれた部分)と「正常の部分」を確実に含む領域をランダムにそれぞれ約1万枚切り出し、合わせて約2万枚の画像(224x224ピクセル)を取得した。
次に、CNNに早期胃がんの検出能力を持たせるため、「転移学習」と呼ばれる学習法を適用しました。転移学習とは、学習を0から行うのではなく、別の目的のために既に学習済みのCNNを使って、少ない学習データで本来の学習目的を達成する手法です。本研究では、ImageNetと呼ばれる大規模画像データセットによって、既に画像分類問題用に学習済みのモデルの一つであるGoogLeNetをCNNの初期モデルとして使用し、上述の約35万枚の画像を用いて、早期胃がん検出のために再学習を行いました。
そして、再学習を終えたCNNに、学習に用いていない約1万枚の画像を使って、それぞれの画像について正しい判断ができるか検証しました。その結果、感度(「がん」画像中、正しく「がん」と判断した割合)は80.0%、特異度(「正常」画像中、正しく「正常」と判断した割合)は94.8%でした。また、陽性的中率[5](「がん」と判断した画像中、実際に「がん」であった割合)は93.4%、陰性的中率[5](「正常」と判断した画像中、実際に「正常」であった割合)は83.6%と極めて高く、胃炎や胃潰瘍と特徴が似ているために判断が難しい例についても、高い確率で判断できることが分かりました。
さらに、内視鏡画像から早期胃がんの領域を自動検出する問題を、再学習を終えたCNNに与えました。早期胃がんには肉眼型分類として主に、明らかな腫瘤状の隆起が認められる「隆起型(Type0-I)」、明らかな隆起や陥凹は認められないが低い隆起が認められる「表面隆起型(Type0-IIa)」、わずかに粘膜の陥凹が認められる「表面陥凹型(Type 0-IIc)」の三つのタイプがあります。これら三つのタイプの早期胃がんの領域を検出させたところ、特に発見が難しい表面陥凹型(Type 0-IIc)でも、領域を自動検出することができました(図2)。本研究では、内視鏡画像を横10個、縦9個のブロックに分割し、各ブロックに再学習を終えたCNNを適用することによって、「がんらしさ」を数値化し、その高低を疑似カラーとして画像上に表示しています。この方法では、検証用に用いた画像の全ブロックのうち、86.2%について正しく「がん」や「正常」の領域を自動検出できていました。
また、画像1枚にかかる処理時間は、画像の入出力にかかる時間を除き、1枚あたり4ミリ秒(0.004秒)と、将来の臨床現場でのリアルタイム自動検出には十分な速度を実現しました。
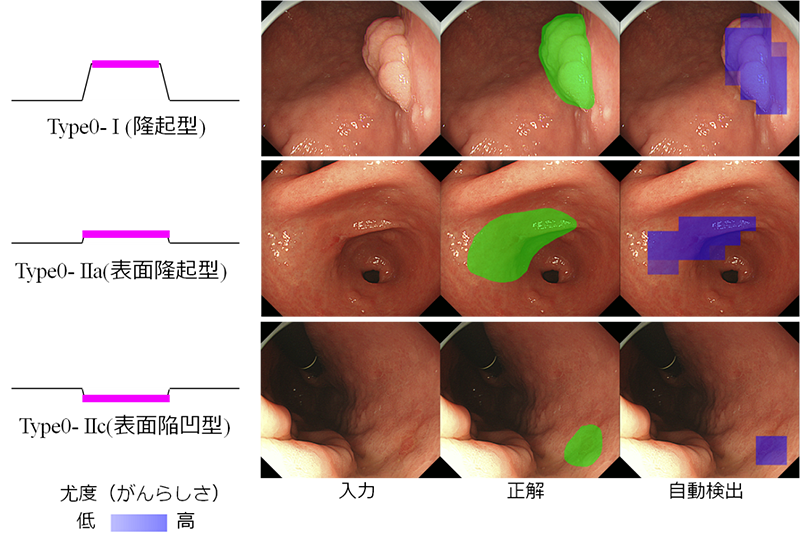
図2 タイプ別の早期胃がんの自動検出例
画像中の緑色で示した領域は、消化器内視鏡の専門医が手作業で早期胃がん領域を示したもので、紫色は自動検出した領域を示している。隆起型(Type0-I)、表面隆起型(Type0-IIa)、表面陥凹型(Type 0-IIc)三つのタイプについて、自動検出に成功した。
3.今後の期待
本研究でCNNの学習用データとして使用した約200枚の画像のうち、医師ががん領域を示した画像はわずか100枚でした。にもかかわらず、コンピュータは平均して約90%という高い確率で「がん」または「正常」を判断できました。この結果は内視鏡専門医の判断に迫るものです。一般的に、機械学習の正解率は学習データの質と量によって決まるため、より多くの良質な情報を学習に利用すれば、さらなる正解率の向上が期待できます。
現在、共同研究チームは日本消化器内視鏡学会によるJapan Endoscopy Database project (JED project) との連携により、早期胃がんの正解画像をより簡単に収集する仕組みを実現しつつあります。さらに、理研の科学技術ハブ推進本部 医科学イノベーションハブ推進プログラムと連携することにより、大量の医療データを自動的に収集し機械学習する仕組みを構築する予定です。これらによって、さらに早期胃がんの検出精度を向上させることが可能です。今後、さらに検証を進め、臨床現場で医師の判断を支援する知能としての早期実用化を目指します。
4.発表情報
- 発表タイトル
Automatic detection of early gastric cancer in endoscopic images using a transferring convolutional neural network - 発表者名
Yoshimasa Sakai, Satoko Takemoto, Keisuke Hori, Masaomi Nishimura, Hiroaki Ikematsu, Tomonori Yano and Hideo Yokota - 学会名称
『40th Annual International Conference of the IEEE Engineering in Medicine and Biology Society』
5.補足説明
- [1] 機械学習
人間の学習能力と同様に、機械(コンピュータ)に学習能力を持たせる手法。データから機械自身が反復的に解析し、ルールを見つけ出すという特徴がある。 - [2] ディープラーニング
機械学習の計算手法の一つで、多層(狭義には4層以上)のニューラルネットワークのこと。画像や動画、テキスト、音声などの分類・識別問題に用いられている。ニューラルネットワークとは、脳機能にみられるいくつかのネットワークを計算機上のシミュレーションで表現することを目指した数学モデルである。 - [3] 畳み込みニューラルネットワーク(CNN)
特に画像の分類や識別で高い性能を発揮するディープラーニングの一つ。あらかじめ与えられていた画像データから画像の特徴量を直接抽出し、ネットワークを学習する。CNNはConvolutional neural networkの略。 - [4] データ拡張
学習用データに変換を加えて、データ量を増やすこと。特に大量の学習データが必要なCNNなどで学習の性能向上に役立つ。変換には、拡大縮小、反転、回転シフト、色変換などがある。 - [5] 陽性的中率、陰性的中率
陽性的中率とは、何らかの検査結果が陽性(今回のケースでは、がん)となった場合に、実際にも陽性(がん)が存在する割合のこと。逆に、陰性的中率とは、何らかの検査結果が陰性(ここでは、正常)となった場合に、実際にも陰性(正常)である割合のこと
6.機関窓口
機関窓口
理化学研究所 広報室 報道担当
電話番号:048-467-9272
ファクス番号:048-462-4715
メールアドレス:ex-press●riken.jp(●は@に置き換えてください)
国立研究開発法人国立がん研究センター
企画戦略局 広報企画室
電話番号:04-7133-1111(代表)
ファクス番号:04-7130-0195
メールアドレス:ncc-admin●ncc.go.jp(●は@に置き換えてください)
関連ファイル
PDFファイルをご覧いただくには、Adobe Readerが必要です。Adobe Readerをお持ちでない方は、バナーのリンク先から無料ダウンロードしてください。