トップページ > 研究所について > OUR RESEARCH FOCUS > 自律的な知識獲得基盤の実装に向けて
キーワード:ゲノム解析, スプライシング, クラウド自律的な知識獲得基盤の実装に向けて

ゲノム解析が広く普及している中で、疾患に関連するゲノム変異の同定は非常に重要な課題になっています。スプライシングに異常を引き起こす変異は、疾患に大きな影響を与える重要なクラスの一つで、15%から60%を占めると言われています。一方で、スプライシングのメカニズムは未解明な部分が多く、スプライシング異常を引き起こすゲノム変異の予測やデータベース化は十分に進んでおりません。
私は長年、公共シークエンスデータを再解析してスプライシング変異をカタログ化することに従事してきました(Shiraishi et al., Genome Research, 2018; PCAWG Transcriptome Core Group, Nature, 2020)。通常スプライシング変異の検出は、ゲノムシークエンス、トランスクリプトームシークエンスがペアで得られているコホートデータを使う方法が一般的でしたが、これらがペアで得られるデータセットは多くはありません。一方で、Sequence Read Archive(SRA)では数十万検体規模のトランスクリプトームデータを自由に取得することが可能で、データの蓄積はさらに加速度的に進んでいます。私は現在、SRAのトランスクリプトームシークエンスデータのみを用いて、スプライシング変異のスクリーニングを行う情報解析基盤の開発に努めています。最近、20 万検体のトランスクリプトームデータからイントロン残存を起こす変異のカタログ化についての研究成果を報告しました(Shiraishi et al., Nature Communication, 2022)。ここでは、Amazon Web Serviceを利用したクラウドベースのプラットフォームと、オンプレミスの計算クラスタのプラットフォームを開発し。SRAとThe Cancer Genome Atlas(TCGA)の総計で230,988件のトランスクリプトームデータの解析を遂行し、約3,000の疾患関連と予測されるイントロン残存を引き起こす変異を同定しました。
現在は、スプライスサイト生成変異、つまり「ゲノム変異によって新規スプライシングモチーフが生成され、それによりスプライシング異常が生じる形式の変異」をトランスクリプトームシークエンスデータのみから検出するアルゴリズムの開発を進めています。実はスプライスサイト生成変異は核酸医薬の主要なターゲットとして大きく注目を集めています。レーバー先天黒内障においてCEP290遺伝子の深部イントロンの変異(c.2991+1655 A>G)をターゲットとした核酸医薬品が臨床試験に進むなど(Russell et al., Nature Medicine, 2022)、様々な遺伝性の疾患原因変異について実際にアンチセンス核酸によるスプライシングの調整が試みられております。
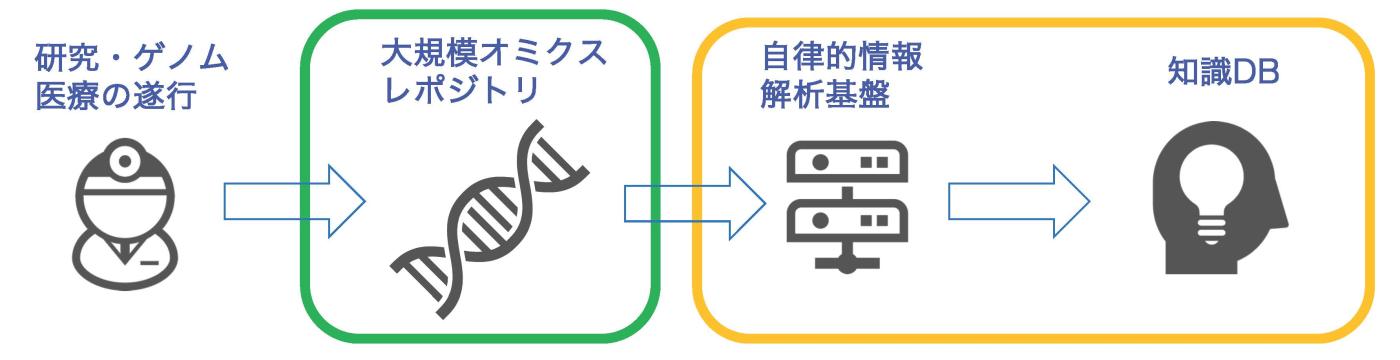
今後のゲノム医療を進める上で、情報技術やAIを活用して疾患関連のゲノム変異をデータベース化することは非常に重要です。将来的には、公共データベースに新しいトランスクリプトームデータが登録されるたびに、自動的に解析プログラムを実行する仕組みを作り、スプライシング変異のデータベースに「知識」を自動的に獲得するようにすることを目指します。さらに、そういった知識の自動獲得の仕組みをスプライシング変異だけではなくより広いゲノム変異のクラスに広げていくことを画策しつつ、今後の研究を進めていこうと思います。
研究者について
ゲノム解析基盤開発分野 分野長 白石 友一
プレスリリース
- ロングリードシークエンスデータから複雑な後天的構造異常を高精度に検出するソフトウェアを世界に先駆けて開発(2023年6月27日)
- 大規模公共トランスクリプトームデータを活用した疾患関連変異の新規スクリーニング手法の開発 蓄積が進むオミクスデータからの自律的な知識獲得基盤の実装に向けて(2022年9月29日)
キーワード
ゲノム解析, スプライシング, クラウド

