トップページ > 研究所について > OUR RESEARCH FOCUS > 膨大な公共オミクスデータから疾患関連変異を探索
キーワード:ゲノム医療、オミクス解析、スプライスサイト変異膨大な公共オミクスデータから疾患関連変異を探索

次世代シークエンス技術の革新・浸透により、膨大なゲノム・トランスクリプトームシークエンスデータの蓄積が進んでいます。
これらのデータは公共リポジトリに登録され、多様な研究者による再解析が行われ、生物学・医学の知見獲得に資する資源となってます。
我々は、公共オミクスデータを用いて疾患に寄与する変異を抽出・カタログ化し、ゲノム医療の重要なリソースとして整備する試みを様々な形で進めています(Shiraishi et al., NatureCommunications, 2022)。
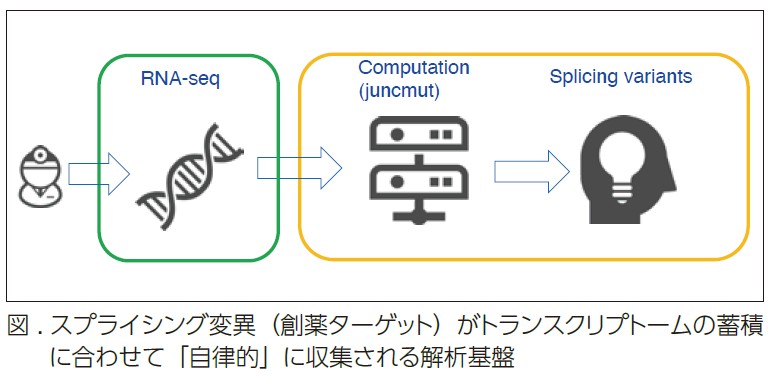
今回の研究では、通常のゲノム解析では見逃されがちで、創薬のターゲットとしても注目される「スプライスサイト生成変異」に着目しました。
我々は、スプライスサイト生成変異をトランスクリプトームシークエンスから高感度に検出するアルゴリズム「juncmut」を開発し、30万件以上のデータに適用して3万件を超える変異を同定しました。
さらに、これらをデータベース「SSCV DB(https://sscvdb.io)」として公開しました。この中には希少疾患やがんの原因となる変異が多数含まれると考えられます。
一方で、SSCV DB の変異の中から疾患関連性が高いものを絞り込むことは非常に困難です。現在、我々は大規模言語モデル(LLM)を用いて、医学的に重要な変異を効率的に選別する新しい解析基盤の開発に取り組んでいます。
プレスリリース・NEWS
疾患原因・創薬標的となるゲノム変異のカタログを構築する新規情報解析基盤を開発(2025年1月9日)
研究者について
ゲノム解析基盤開発分野 分野長 白石 友一
キーワード
ゲノム医療、オミクス解析、スプライスサイト変異、SSCV_DB

